Hadoop Distributed File System
- 易于拓展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
NameNode
- Namenode是一个中心服务器,==单一节点==(简化系统的设计和实现),==负责管理文件系统的名字空间(namespace)以及客户端对文件的访问==。
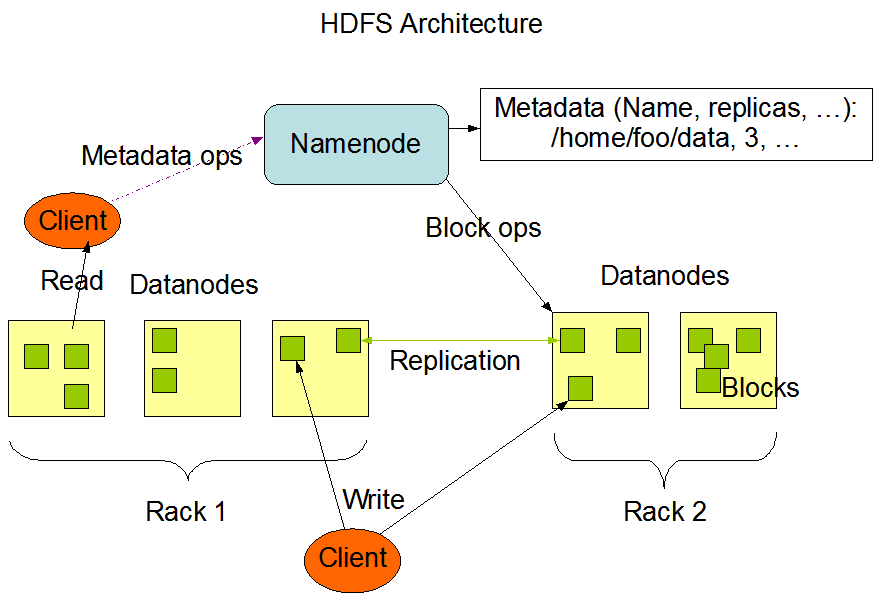
- 文件操作,==NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode==,只会询问他跟哪个DataNode联系,否则NameNode会成为系统的瓶颈。
- 副本存放在那些DataNode上是由NameNode控制的,根据全局情况作出块放置决定,==读取文件时NameNode尽量让用户先读取最近的副本==,降低带块消耗和读取时延。
- ==NameNode全权管理数据块的赋值==,它周期性地从集群中的==每个DataNode接收心跳信号和块状态报告(Blockreport)==。接手到心跳信号意味着该DataNode节点工作正常。块状态报告包含了一个该==DataNode上所有数据块==的列表。
DataNode
- 一个==数据块在DataNode以文件存储在磁盘上==,包括两个文件,一个是数据本身,一个是==元数据包括数据块的长度,块数据的校验和,以及时间戳==。
- DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令,如复制块数据到另一台机器,或者删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
文件
- ==文件切分成块==(默认128M),以块为单位,==每个块有多个副本存储在不同的机器上==,副本数可在文件生成时指定(默认3)。
- NameNode是主节点,==存储文件的元数据==如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的快列表以及块所在的DataNode等待。
- DataNode在本地文件==系统存储文件块数据==,以及==块数据的校验和==。
- ==可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容==。
HDFS Architecture
Data Replication
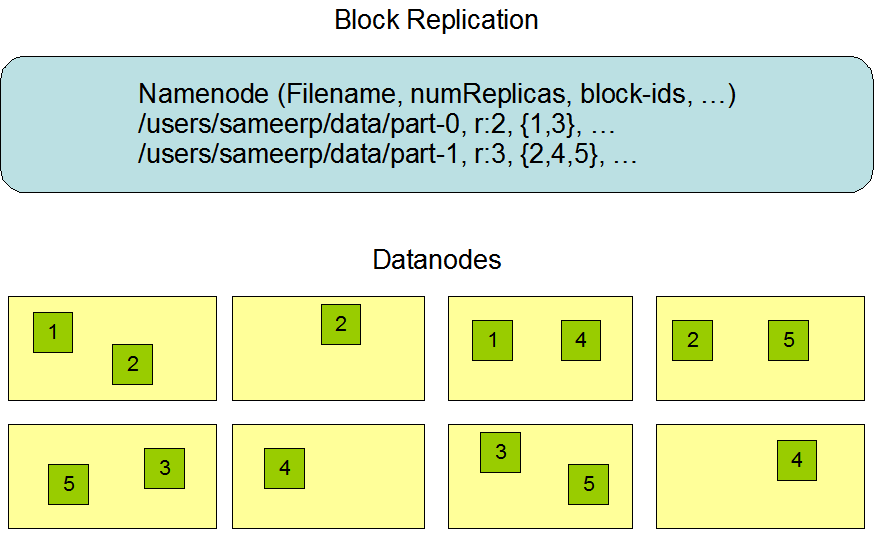
副本放置策略
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
数据损坏(corruption)处理
- 当DataNode读取block的时候,它会计算checksum
- 如果计算后的checksum,与block创建时值不一样,说明该block已经损坏。
- Client读取其他DataNode上的block
- NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数。
- DataNode在其文件创建后三周验证其checksum。